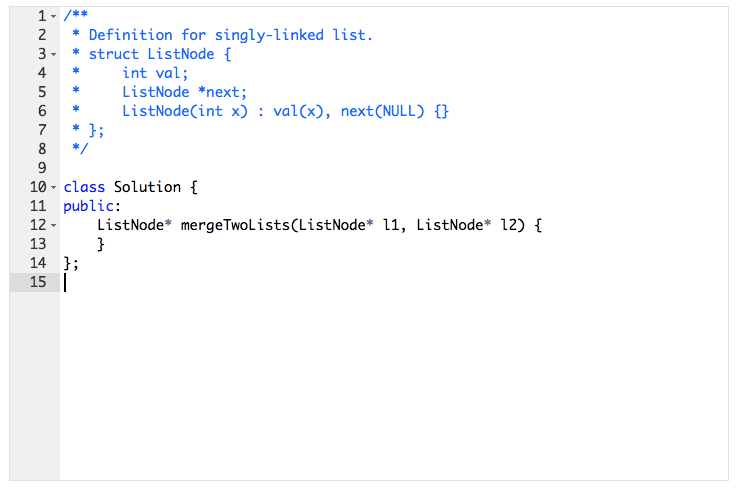
Solution #1: Classic STL Solution, Immutable parameters
Right-click and "Save Image as ..." to get a better look at this image!
// Solution #1
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
std::list<int> intList;
ListNode* h1 = l1, *h2 = l2;
while ( h1!=NULL ) {
intList.push_back(h1->val);
h1 = h1->next;
}
while ( h2!=NULL ) {
intList.push_back(h2->val);
h2 = h2->next;
}
ListNode* listNode = new ListNode(0), *p = listNode, *result = listNode;
intList.sort();
std::list<int>::const_iterator iterator;
for (iterator = intList.begin(); iterator != intList.end(); ++iterator) {
int value = *iterator;
p = listNode;
listNode->val = value;
listNode = new ListNode(0);
p->next = listNode;
}
p->next = NULL;
if ( p == listNode ) {
delete listNode;
return NULL;
}
return result;
}
};
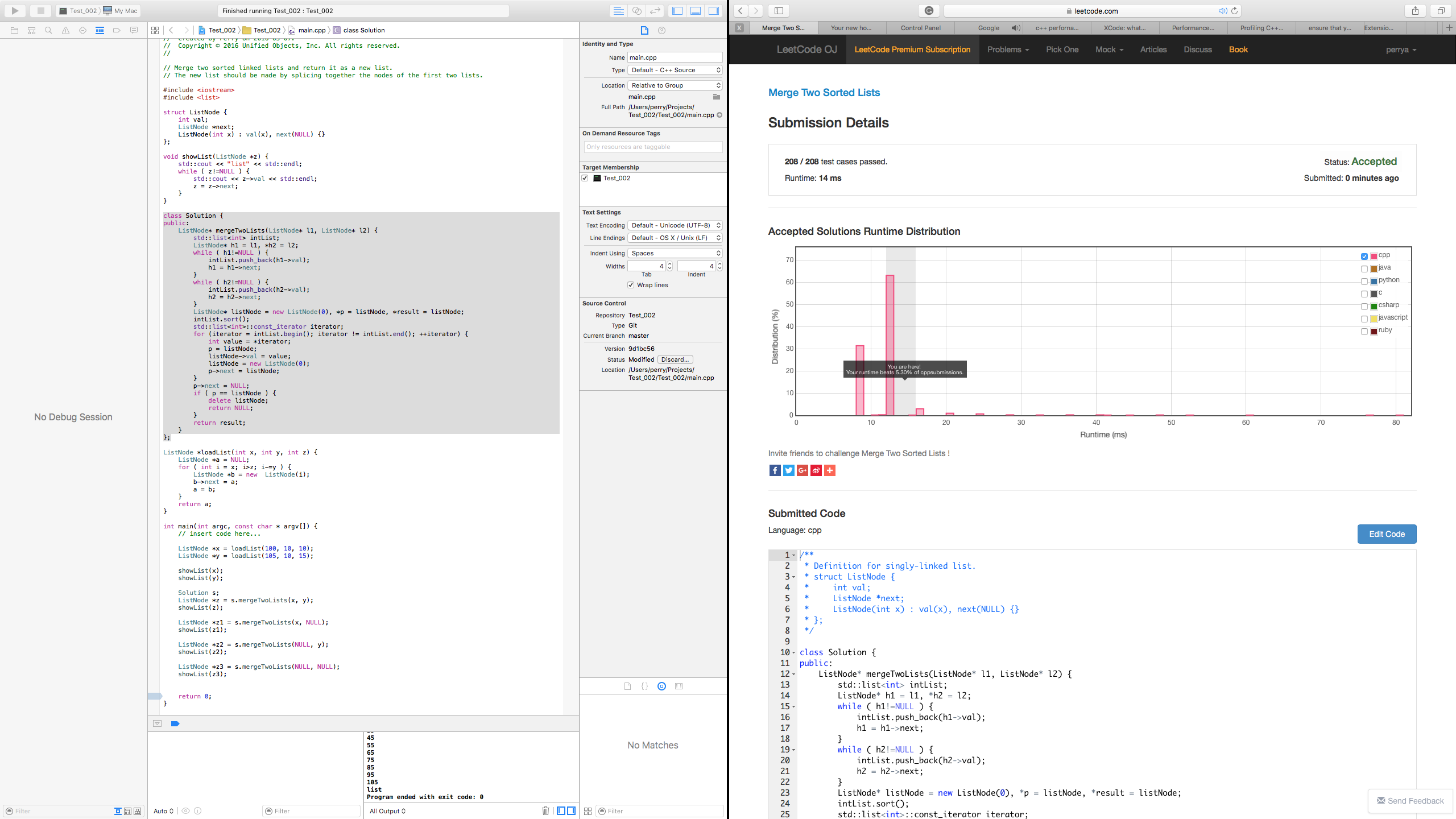
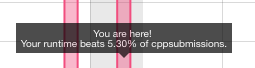
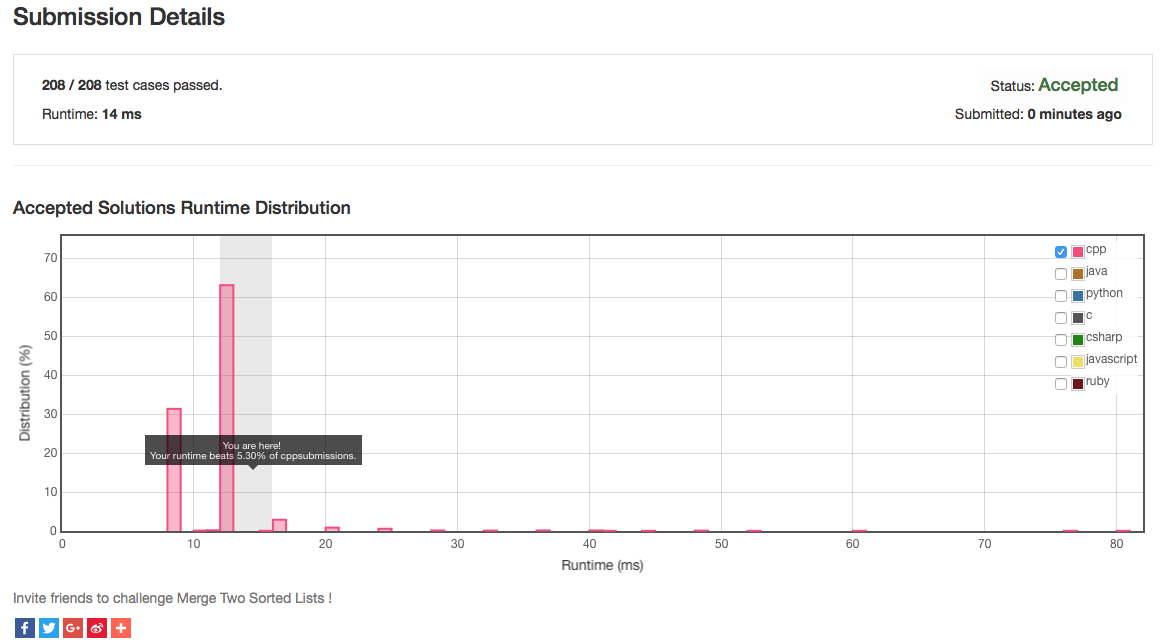
When I submitted my solution to the LeetCode OJ database for approval I was rather surprised to see a graph comparing my results with many others. Unfortunately for me I misread the rating on the report that suggested that my solution may not be the most efficient:
Right-click and "Save Image as ..." to get a better look at this image!
Solution #2: Classic Heap Sort Solution, Immutable parameters
Right-click and "Save Image as ..." to get a better look at this image!
// Solution #2
void MAX_HEAPIFY(int a[], int i, int n)
{
int l,r,largest,loc;
l=2*i;
r=(2*i+1);
if((l<=n)&&a[l]>a[i])
largest=l;
else
largest=i;
if((r<=n)&&(a[r]>a[largest]))
largest=r;
if(largest!=i)
{
loc=a[i];
a[i]=a[largest];
a[largest]=loc;
MAX_HEAPIFY(a, largest,n);
}
}
void BUILD_MAX_HEAP(int a[], int n)
{
for(int k = n/2; k >= 1; k--)
{
MAX_HEAPIFY(a, k, n);
}
}
void HEAPSORT(int a[], int n)
{
BUILD_MAX_HEAP(a,n);
int i, temp;
for (i = n; i >= 2; i--)
{
temp = a[i];
a[i] = a[1];
a[1] = temp;
MAX_HEAPIFY(a, 1, i - 1);
}
}
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* h1 = l1, *h2 = l2;
int n = 0;
while ( h1!=NULL ) {
n++;
h1 = h1->next;
}
while ( h2!=NULL ) {
n++;
h2 = h2->next;
}
h1 = l1, h2 = l2;
int a[n], i=1;
while ( h1!=NULL ) {
a[i++] = h1->val;
h1 = h1->next;
}
while ( h2!=NULL ) {
a[i++] = h2->val;
h2 = h2->next;
}
HEAPSORT(a, n);
ListNode* listNode = new ListNode(0), *p = listNode, *result = listNode;
for (int i = 1; i <= n; i++) {
int value = a[i];
p = listNode;
listNode->val = value;
listNode = new ListNode(0);
p->next = listNode;
}
p->next = NULL;
if ( p == listNode ) {
delete listNode;
return NULL;
}
return result;
}
};
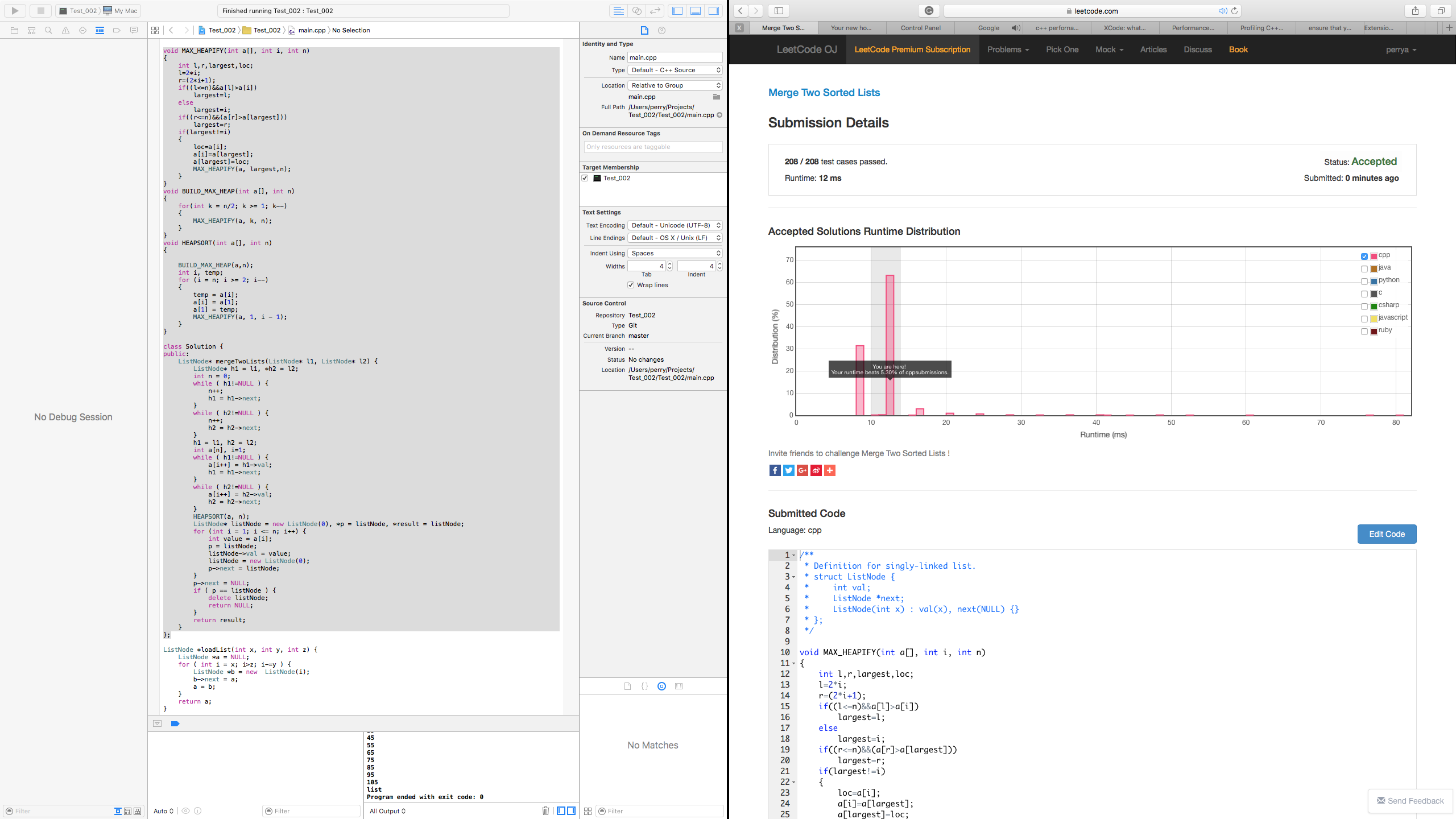
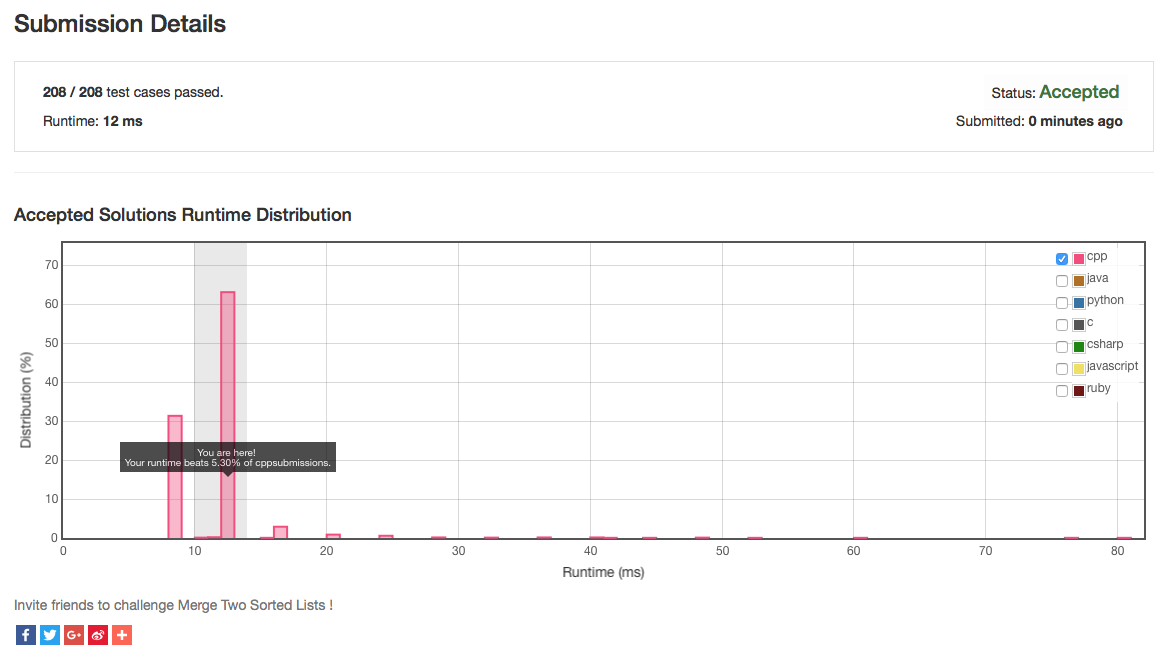
What amazed me however is that the benchmarks provided by LeetCode OJ were practically identical to the original STL solution.
Right-click and "Save Image as ..." to get a better look at this image!
Solution #3: Classic Quick Sort Solution, Immutable parameters
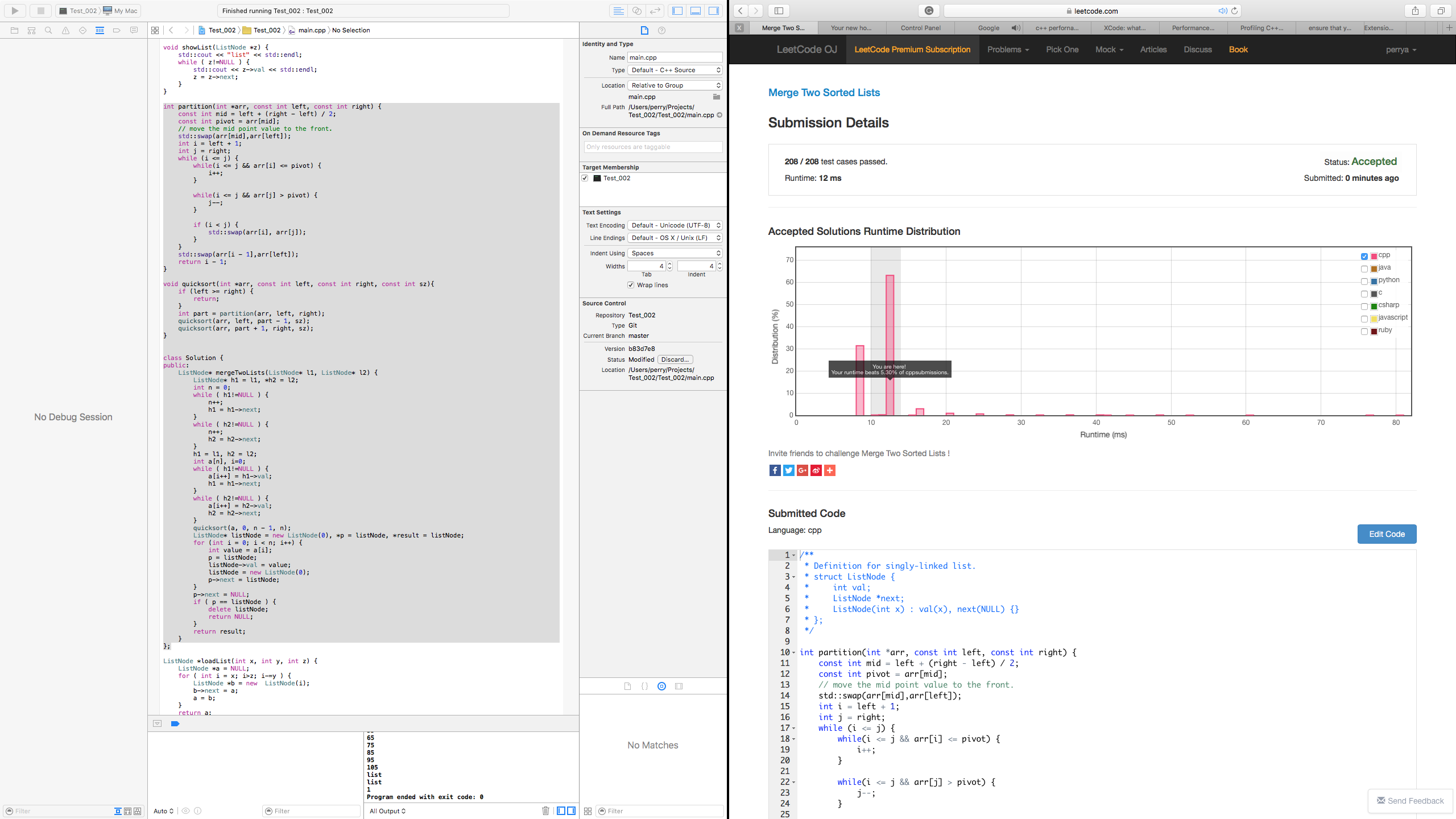
Right-click and "Save Image as ..." to get a better look at this image!
// Solution #3
int partition(int *arr, const int left, const int right) {
const int mid = left + (right - left) / 2;
const int pivot = arr[mid];
// move the mid point value to the front.
std::swap(arr[mid],arr[left]);
int i = left + 1;
int j = right;
while (i <= j) {
while(i <= j && arr[i] <= pivot) {
i++;
}
while(i <= j && arr[j] > pivot) {
j--;
}
if (i < j) {
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i - 1],arr[left]);
return i - 1;
}
void quicksort(int *arr, const int left, const int right, const int sz){
if (left >= right) {
return;
}
int part = partition(arr, left, right);
quicksort(arr, left, part - 1, sz);
quicksort(arr, part + 1, right, sz);
}
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* h1 = l1, *h2 = l2;
int n = 0;
while ( h1!=NULL ) {
n++;
h1 = h1->next;
}
while ( h2!=NULL ) {
n++;
h2 = h2->next;
}
h1 = l1, h2 = l2;
int a[n], i=0;
while ( h1!=NULL ) {
a[i++] = h1->val;
h1 = h1->next;
}
while ( h2!=NULL ) {
a[i++] = h2->val;
h2 = h2->next;
}
quicksort(a, 0, n - 1, n);
ListNode* listNode = new ListNode(0), *p = listNode, *result = listNode;
for (int i = 0; i < n; i++) {
int value = a[i];
p = listNode;
listNode->val = value;
listNode = new ListNode(0);
p->next = listNode;
}
p->next = NULL;
if ( p == listNode ) {
delete listNode;
return NULL;
}
return result;
}
};
Despite utilizing a different, more efficient sorting algorithm however there was almost no change in the performance reported by LeetCode OJ:
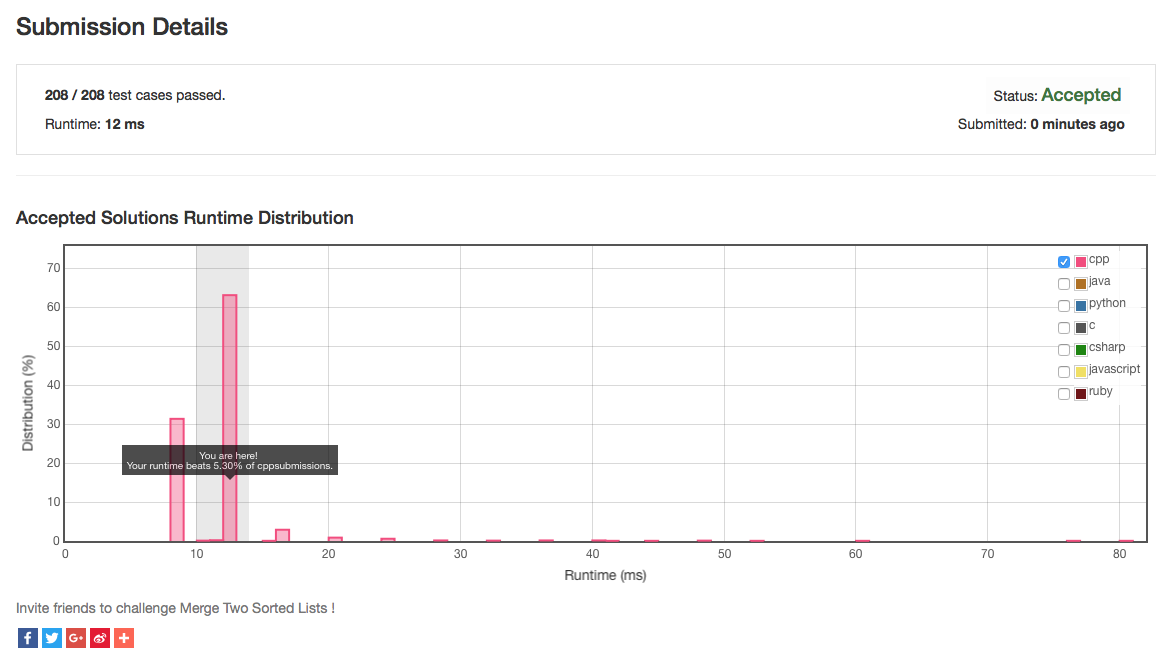
Right-click and "Save Image as ..." to get a better look at this image!
Solution #4: Classic STL Solution, Mutable parameters
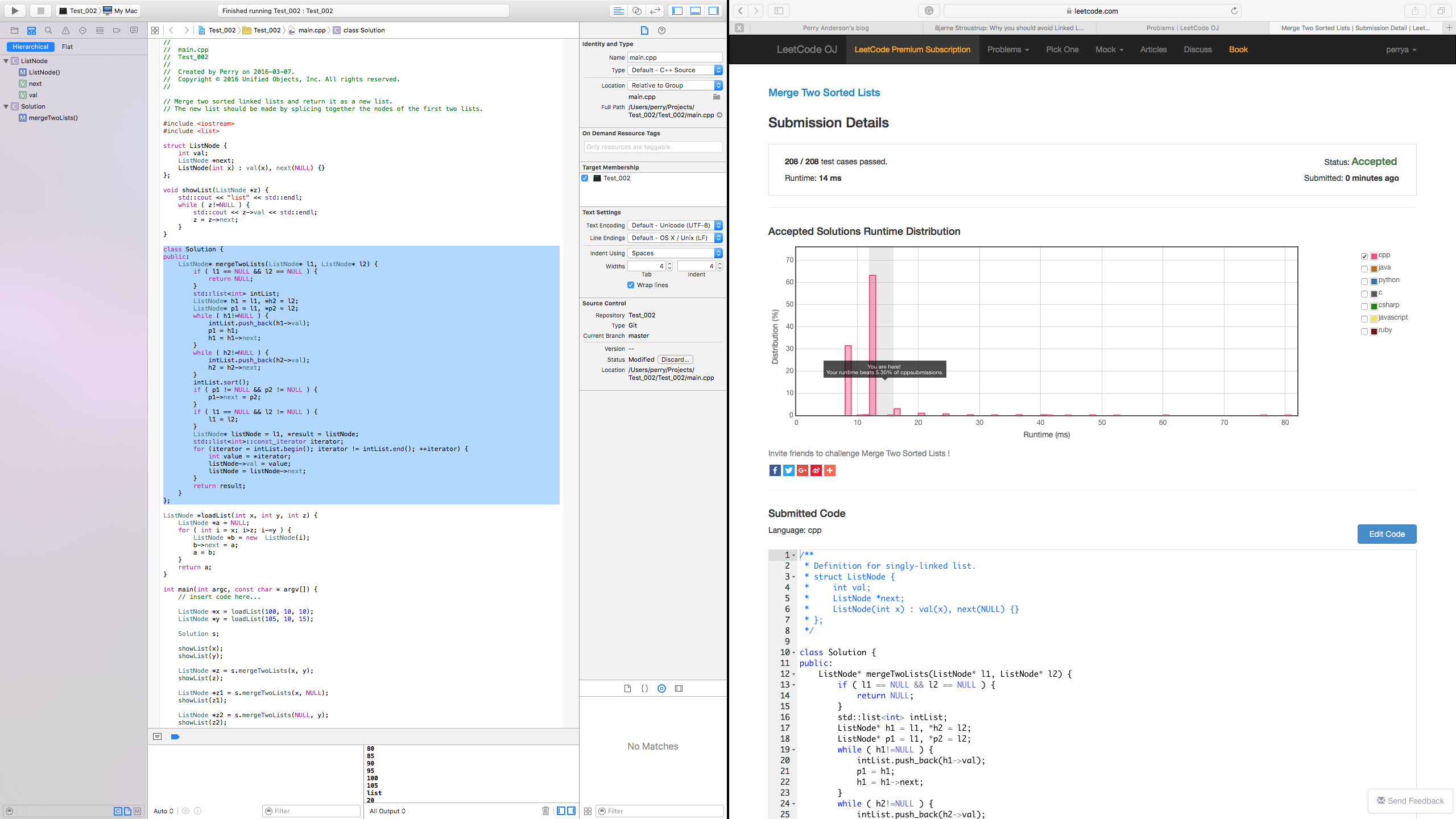
Right-click and "Save Image as ..." to get a better look at this image!
// Solution #4 (optimized)
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if ( l1 == NULL && l2 == NULL ) {
return NULL;
}
std::list<int> intList;
ListNode* h1 = l1, *h2 = l2;
ListNode* p1 = l1, *p2 = l2;
while ( h1!=NULL ) {
intList.push_back(h1->val);
p1 = h1;
h1 = h1->next;
}
while ( h2!=NULL ) {
intList.push_back(h2->val);
h2 = h2->next;
}
intList.sort();
if ( p1 != NULL && p2 != NULL ) {
p1->next = p2;
}
if ( l1 == NULL && l2 != NULL ) {
l1 = l2;
}
ListNode* listNode = l1, *result = listNode;
std::list<int>::const_iterator iterator;
for (iterator = intList.begin(); iterator != intList.end(); ++iterator) {
int value = *iterator;
listNode->val = value;
listNode = listNode->next;
}
return result;
}
};
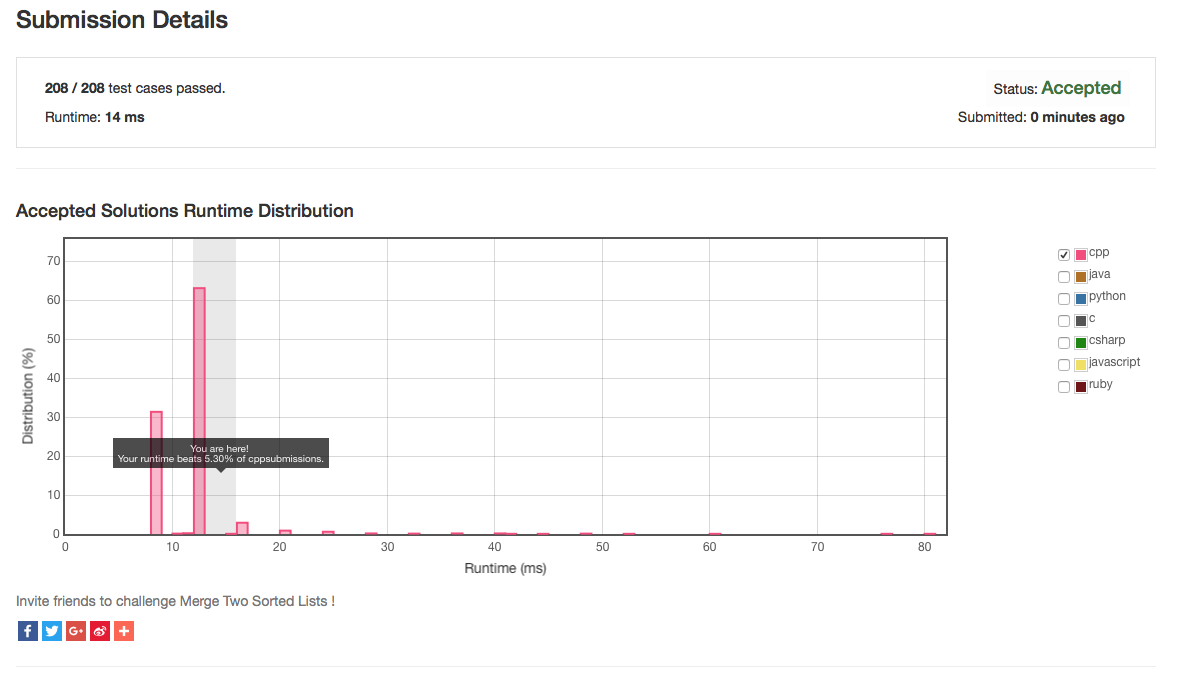
Right-click and "Save Image as ..." to get a better look at this image!
Solution #5: Classic Quick Sort Solution, Mutable parameters
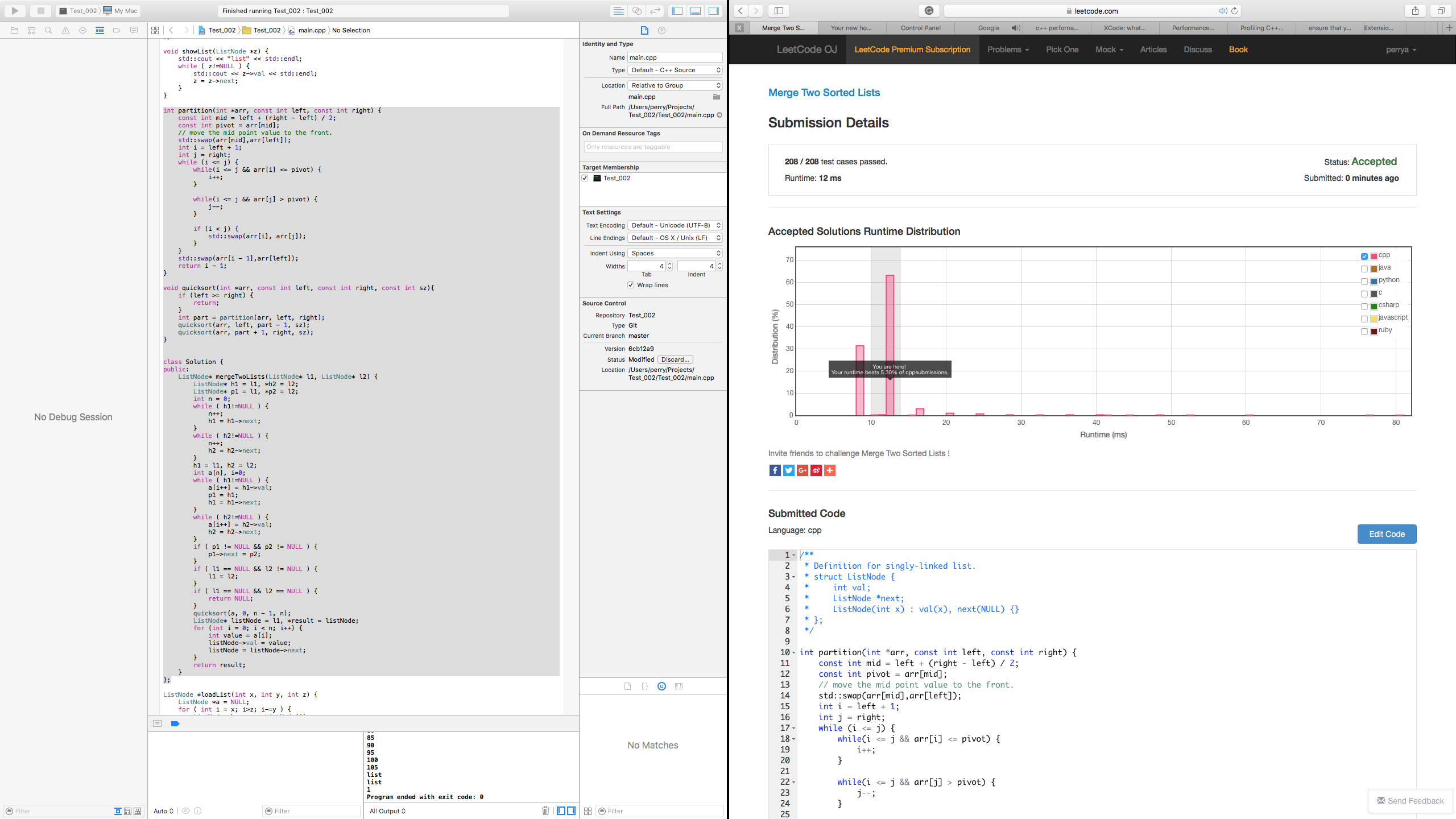
Right-click and "Save Image as ..." to get a better look at this image!
// Solution #5
int partition(int *arr, const int left, const int right) {
const int mid = left + (right - left) / 2;
const int pivot = arr[mid];
// move the mid point value to the front.
std::swap(arr[mid],arr[left]);
int i = left + 1;
int j = right;
while (i <= j) {
while(i <= j && arr[i] <= pivot) {
i++;
}
while(i <= j && arr[j] > pivot) {
j--;
}
if (i < j) {
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i - 1],arr[left]);
return i - 1;
}
void quicksort(int *arr, const int left, const int right, const int sz){
if (left >= right) {
return;
}
int part = partition(arr, left, right);
quicksort(arr, left, part - 1, sz);
quicksort(arr, part + 1, right, sz);
}
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* h1 = l1, *h2 = l2;
ListNode* p1 = l1, *p2 = l2;
int n = 0;
while ( h1!=NULL ) {
n++;
h1 = h1->next;
}
while ( h2!=NULL ) {
n++;
h2 = h2->next;
}
h1 = l1, h2 = l2;
int a[n], i=0;
while ( h1!=NULL ) {
a[i++] = h1->val;
p1 = h1;
h1 = h1->next;
}
while ( h2!=NULL ) {
a[i++] = h2->val;
h2 = h2->next;
}
if ( p1 != NULL && p2 != NULL ) {
p1->next = p2;
}
if ( l1 == NULL && l2 != NULL ) {
l1 = l2;
}
if ( l1 == NULL && l2 == NULL ) {
return NULL;
}
quicksort(a, 0, n - 1, n);
ListNode* listNode = l1, *result = listNode;
for (int i = 0; i < n; i++) {
int value = a[i];
listNode->val = value;
listNode = listNode->next;
}
return result;
}
};
Right-click and "Save Image as ..." to get a better look at this image!
Solution #6: Classic Heap Sort Solution, Mutable parameters
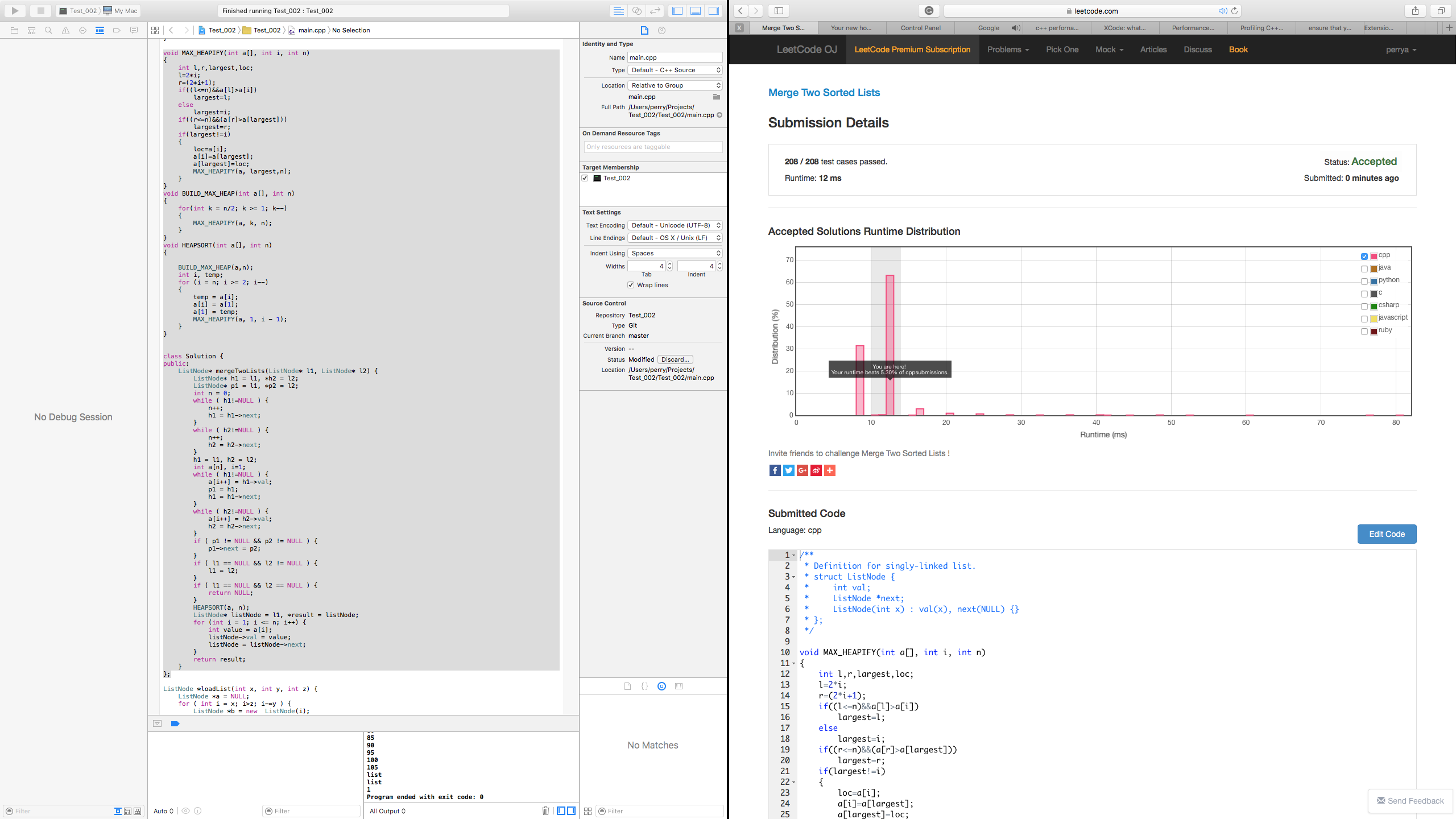
Right-click and "Save Image as ..." to get a better look at this image!
// Solution #6
void MAX_HEAPIFY(int a[], int i, int n)
{
int l,r,largest,loc;
l=2*i;
r=(2*i+1);
if((l<=n)&&a[l]>a[i])
largest=l;
else
largest=i;
if((r<=n)&&(a[r]>a[largest]))
largest=r;
if(largest!=i)
{
loc=a[i];
a[i]=a[largest];
a[largest]=loc;
MAX_HEAPIFY(a, largest,n);
}
}
void BUILD_MAX_HEAP(int a[], int n)
{
for(int k = n/2; k >= 1; k--)
{
MAX_HEAPIFY(a, k, n);
}
}
void HEAPSORT(int a[], int n)
{
BUILD_MAX_HEAP(a,n);
int i, temp;
for (i = n; i >= 2; i--)
{
temp = a[i];
a[i] = a[1];
a[1] = temp;
MAX_HEAPIFY(a, 1, i - 1);
}
}
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* h1 = l1, *h2 = l2;
ListNode* p1 = l1, *p2 = l2;
int n = 0;
while ( h1!=NULL ) {
n++;
h1 = h1->next;
}
while ( h2!=NULL ) {
n++;
h2 = h2->next;
}
h1 = l1, h2 = l2;
int a[n], i=1;
while ( h1!=NULL ) {
a[i++] = h1->val;
p1 = h1;
h1 = h1->next;
}
while ( h2!=NULL ) {
a[i++] = h2->val;
h2 = h2->next;
}
if ( p1 != NULL && p2 != NULL ) {
p1->next = p2;
}
if ( l1 == NULL && l2 != NULL ) {
l1 = l2;
}
if ( l1 == NULL && l2 == NULL ) {
return NULL;
}
HEAPSORT(a, n);
ListNode* listNode = l1, *result = listNode;
for (int i = 1; i <= n; i++) {
int value = a[i];
listNode->val = value;
listNode = listNode->next;
}
return result;
}
};
Right-click and "Save Image as ..." to get a better look at this image!
Further that the message "Your runtime beats 5.30% of cpp submissions." was misleading. In fact, a closer inspection of the graph provided by LeetCode OJ showed my solution in the top 94.7% bracket of posted solutions. It appears the graph was not entirely accurate based on the number of submissions, it was probably in err. For example, the graph goes from left to right where as the left of the graph indicates time of execution. My based on the 5.30% it was giving me, it suggested a lot of room for improvement when in effect, my solution was already in the top ten percent of submissions.
Solution #7: Intergrated STL/Quick Sort Solution, Mutable parameters
Synopsis:
// Solution #1
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
std::list<int> intList;
ListNode* h1 = l1, *h2 = l2;
while ( h1!=NULL ) {
intList.push_back(h1->val);
h1 = h1->next;
}
while ( h2!=NULL ) {
intList.push_back(h2->val);
h2 = h2->next;
}
ListNode* listNode = new ListNode(0), *p = listNode, *result = listNode;
intList.sort();
std::list<int>::const_iterator iterator;
for (iterator = intList.begin(); iterator != intList.end(); ++iterator) {
int value = *iterator;
p = listNode;
listNode->val = value;
listNode = new ListNode(0);
p->next = listNode;
}
p->next = NULL;
if ( p == listNode ) {
delete listNode;
return NULL;
}
return result;
}
};
// Solution #4 ( aka. Solution #1 version 2 )
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if ( l1 == NULL && l2 == NULL ) {
return NULL;
}
std::list<int> intList;
ListNode* h1 = l1, *h2 = l2;
ListNode* p1 = l1, *p2 = l2;
while ( h1!=NULL ) {
intList.push_back(h1->val);
p1 = h1;
h1 = h1->next;
}
while ( h2!=NULL ) {
intList.push_back(h2->val);
h2 = h2->next;
}
intList.sort();
if ( p1 != NULL && p2 != NULL ) {
p1->next = p2;
}
if ( l1 == NULL && l2 != NULL ) {
l1 = l2;
}
ListNode* listNode = l1, *result = listNode;
std::list<int>::const_iterator iterator;
for (iterator = intList.begin(); iterator != intList.end(); ++iterator) {
int value = *iterator;
listNode->val = value;
listNode = listNode->next;
}
return result;
}
};
Word to the wise: Know when to say when!
Design by Contract is a popular concept among Eiffel programmers, essentially you determine ahead of time what a function has to do and you ensure that the function to be written only does what is expected. This includes checking the parameters for correct values before any processing takes place. The lesson to be gleaned from Design by Contract in my humble opinion is that get things done faster but making things simpler on yourself. Technically speaking, even though I didn't use a pure link list solution to this problem, by way of the STL I met the specification and delivered a working solution within an hour of the task at hand.
Merge two sorted linked lists and return it as a new list.
The new list should be made by splicing together the nodes of the first two lists.
The second version of Solution #1 meets both these requirements. Technically, by way of the STL framework, I have met the specification of this task. All in a days work!
The alternative method of piecing together a link list merge solution without the use of STL comparatively takes a lot longer given the many complications related to managing a link list. Based on what I read from Bjorne's ideals on why they developed the STL in the first place, I can easily appreciate today that if I had a boss that needed this done today there would be no contest, the STL solution gets things done. I say this out of experience. Quite often a boss needs a solution that works today and will quite often settle for an imperfect solution. It takes experience to know when to break down a problem in smaller parts to be delivered much more immediately as oppose to delaying progress while waiting for a more perfect solution.
Rational Unified Process
Also, to those of you familiar with the Rational Unified Process and it's Iteration Drive Development methodology, both solutions can compliment each other quite nicely. In other words, in a professional environment, if the situation called for memory and performance efficient solution for the long term, then a shorter term STL solution can be established first, then time given for a more specific solution for the long term if the situation demanded it.
Solution #8: Non-STL Merge solution assuming Two Sorted Lists
// Solution #8 ( incomplete )
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if ( l1==NULL && l2==NULL )
return NULL;
if ( l1==NULL && l2!=NULL )
return l2;
if ( l1!=NULL && l2==NULL )
return l1;
ListNode* result = l1;
if ( l2->val <= l1->val )
result = l2;
while ( l1!=NULL && l2!=NULL ) {
while ( l1!=NULL && l2!=NULL && l2->val <= l1->val ) {
while ( l2->next!=NULL && l2->next->val <= l1->val )
l2 = l2->next;
ListNode* a = l1->next;
ListNode* b = l2->next;
l2->next = l1;
if ( b!=NULL )
l1->next = b;
l1 = a;
l2 = b;
}
while ( l1!=NULL && l2!=NULL && l2->val > l1->val ) {
while ( l1->next!=NULL && l1->next->val < l2->val )
l1 = l1->next;
ListNode* a = l1->next;
ListNode* b = l2->next;
l1->next = l2;
if ( a!=NULL )
l1->next = a;
l1 = a;
l2 = b;
}
}
return result;
}
};
Day 1 Keynote, Bjarne Stroustrup: C++11 Style
What you have seen here is a typical day in software development for me. You utilize the tools you have available combined with what you understand as current and correct feedback. As for misunderstanding the task at hand "Merge Two Sorted Lists" it really doesn't matter as misunderstandings happen all the time. This is why we have the Rational Unified Process and Use Case driven development. In essence, the policy to make the time to take the time or vise-versa. To understand the customer better before any coding takes place as minor misunderstandings like this happen in life. However, the STL solution still solved both cases and did so within an hour, the only difference being that a pure non-STL solution might be more efficient. However, in real life, such efficiencies often come at the cost of time and money and in today's business world time is money. No where in the specification did the task at hand indicate that it had to be the fastest solution in the universe, hence I met the terms of the contract and saved my imaginary customer a tonne of money in consulting fees or lost production time. I was just curious as to why my solution wasn't considered near the top of the list as far as LeetCode OJ was concerned, hence the other versions of my solution. When time permits I will take the time to put in a proper non-STL version just to see if I hit a much higher rating. However I will also be noting just how long it took to put together said solution and compare the amount of time it took to re-invent the wheel verses my initial STL version which was completed within an hour of the task assignment. Had this been a real time engineering application, as is the case in my background in SCADA systems, this would have been a typical day at the office. To paraphrase the great Philippe Kahn: First you get it to work, then you get it to work better!
Thank you for taking the time to review this presentation.